목차
MLP(Multi Layer Perceptron)란?
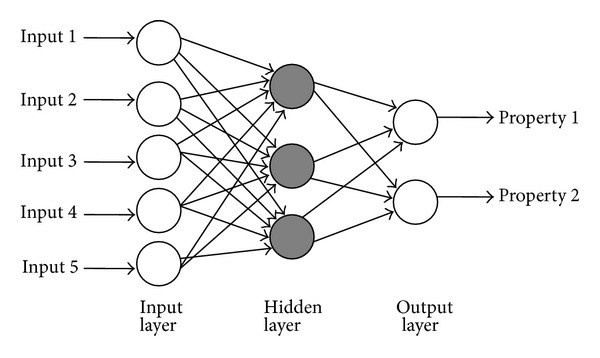
단층 퍼셉트론에서 은닉층이 추가된 신경망을 말한다. 단층 퍼셉트론은 입력층, 출력층으로 구성되어 있다. 다층 퍼셉트론은 입력층, 출력층, 은닉층으로 구성된다. 다층 퍼셉트론은 입력층에서 출력층 방향으로만 연산이 진행된다. 이러한 신경망을 피드 포워드 신경망(Feed-Forward Neural Network, FFNN)이라 부른다.
텍스트 데이터를 고정 길이의 벡터로 변환하는 방법
텍스트를 벡터 데이터로 변환하는 방법은 One-Hot Encoding, Bag of Words(BOW), Count Vector, TF-IDF 등이 있다.
여기서 Bag of Words를 사용해 텍스트를 변환해보겠다.
*Bag of Words(BoW)란?
- 단어들의 출현 횟수를 이용해 텍스트 데이터를 수치화하는 방법이다.
- 단어마다 ID를 부여하고 각 인덱스마다 단어의 빈도 수를 기록하는 방식이다.
아래 예시를 통해 살펴보자.
"몇 번을 쓰러지더라도 몇 번을 무너지더라도 다시 일어나라 ." 라는 문장을 BoW로 나타내보자.
일단 형태소 분석부터 해야한다. 형태소 분석 결과는 다음과 같다.
| 몇 | 번 | 을 | 쓰러지다 | 몇 | 번 | 을 | 무너지다 | 다시 | 일어나다 |
각 형태소마다 ID를 부여하고 단어의 출현 빈도를 세어보면 아래와 같이 나타낼 수 있다.
| 형태소 | 몇 | 번 | 을 | 쓰러지다 | 무너지다 | 다시 | 일어나다 |
| ID | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 출현 빈도 | 2 | 2 | 2 | 1 | 1 | 1 | 1 |
<실습1 - 단어를 ID로 변환하고 출현 횟수 구하기>
import os, glob, json
root_dir="./newstext"
dic_file=root_dir+"/word-dic.json"
data_file=root_dir+"/data.json"
data_file_min=root_dir+"/data-mini.json"
#어구를 자르고 ID로 변환하기
word_dic={"_MAX":0}
def text_to_ids(text):
text=text.strip()
words=text.split(" ")
result=[]
for n in words:
n=n.strip()
if n=="":continue
if not n in word_dic: #단어가 word_dic에 없으면
wid=word_dic[n]=word_dic["_MAX"] #단어를 word_dic에 추가하고 "_MAX"의 value값을 단어의 id값으로 가짐
word_dic["_MAX"]+=1 #"_MAX" 값은 이후에도 id값으로 사용되야 하기 때문에 1을 더함
# print(wid, n)
else:
wid=word_dic[n]
result.append(wid) #result에 단어 id값 추가
return result
#파일 읽고 고정 길이의 배열 리턴하기
def file_to_ids(fname):
with open(fname, "r", encoding='utf-8') as f: #파일이 한글이라서 인코딩필요
text=f.read()
return text_to_ids(text) #파일에서 읽어온 텍스트를 단어로 구분해 id로 변환
#딕셔너리에 단어 모두 등록하기
def register_dic():
files=glob.glob(root_dir+"/*/*.wakati", recursive=True)
for i in files:
file_to_ids(i)
#파일 내부의 단어 세기
def count_file_freq(fname):
cnt=[0 for n in range(word_dic["_MAX"])] #word_dic에 등록된 단어 수만큼 0이 존재함. cnt = [0 0 0 0 ... 0 0 ]
with open(fname, "r", encoding='utf-8') as f:
text=f.read().strip()
ids=text_to_ids(text)
for wid in ids: #단어별로 출현 빈도 count
cnt[wid]+=1 #해당 단어 id별로 count
return cnt
#카테고리마다 파일 읽어 들이기
def count_freq(limit=0):
X=[]
Y=[]
max_words=word_dic["_MAX"]
cat_names=[]
for cat in os.listdir(root_dir): #cat변수 : 뉴스 데이터에서 카테고리 별 디렉토리 이름
cat_dir=root_dir+"/"+cat
if not os.path.isdir(cat_dir): continue #해당 파일이 디렉터리 파일인지 확인
cat_idx=len(cat_names)
cat_names.append(cat)
files=glob.glob(cat_dir+"/*.wakati")
i=0
for path in files:
# print(path)
cnt=count_file_freq(path) #파일별 단어 출현 빈도 count한 거 저장
X.append(cnt)
Y.append(cat_idx)
if limit>0:
if i>limit: break
i+=1
return X,Y
#단어 딕셔너리 만들기
if os.path.exists(dic_file):
word_dic=json.load(open(dic_file))
else:
register_dic()
json.dump(word_dic, open(dic_file, "w"))
#벡터를 파일로 출력하기
#테스트 목적의 소규모 데이터 만들기
X, Y=count_freq(20)
json.dump({"X":X,"Y":Y}, open(data_file_min, "w"))
#전체 데이터를 기반으로 데이터 만들기
X, Y=count_freq()
json.dump({"X":X,"Y":Y}, open(data_file, "w"))
print("ok")
단어를 BoW 방식을 사용해서 빈도를 기반으로 텍스트 데이터를 수치화한다.
수치화한 데이터는 카테고리 별로 저장된다.
이 코드를 실행하고 나면 data-mini.json, data.json, word-dic.json 파일이 생성된다.
생성된 데이터를 활용해 실습2에서 MLP를 활용한 텍스트 분류를 할 것이다.
<실습2 - MLP로 텍스트 분류하기>
실습 1은 분류를 위한 데이터를 만드는 과정이었다. 실습1에서 생성한 파일을 사용해 기사 카테고리 별로 텍스트 분류를 해보자.
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.wrappers.scikit_learn import KerasClassifier
from keras.utils import np_utils
from sklearn.model_selection import train_test_split
from sklearn import model_selection, metrics
import json
max_words=56681 #입력 단어 수 : word-dic.json 파일 참고
nb_classes = 6 #카테고리 6개
batch_size=64
epochs=20
#MLP 모델 생성
def build_model():
model=Sequential()
model.add(Dense(512, input_shape=(max_words,)))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
return model
#데이터 읽어오기
data=json.load(open("./newstext/data-mini.json"))
#data=json.load(open("./newstext/data.json"))
X=data["X"] #텍스트를 나타내는 데이터
Y=data["Y"] #카테고리 데이터
#학습하기
X_train, X_test, Y_train, Y_test = train_test_split(X, Y)
Y_train=np_utils.to_categorical(Y_train, nb_classes)
print(len(X_train), len(Y_train))
model=KerasClassifier(
build_fn=build_model,
epochs=nb_epoch,
batch_size=batch_size)
model.fit(X_train, Y_train)
#예측하기
y=model.predict(X_test)
ac_score=metrics.accuracy_score(Y_test, y)
cl_report=metrics.classfication_report(Y_test, y)
print("정답률 =", ac_score)
print("리포트=\n", cl_report)MLP 모델 생성과정을 자세히 보자.
model=Sequential() 으로 순차적으로 레이어 층을 더해주는 모델을 생성한다.
model.add(Dense(512, input_shape=(max_words,))) #모델이 max_words만큼 즉 (*, 56681) 형태의 배열을 인풋으로 받고 (*, 512) 형태의 배열을 출력한다는 의미
model.add(Activation('relu')) #사용할 활성화 함수 지정
model.add(Dropout(0.5)) #인풋에 드롭아웃을 적용해 과적합을 방지할 수 있음
model.add(Dense(nb_classes)) #위에서 첫번째 레이어를 이미 추가했기 때문에 이번에는 인풋의 크기를 특정할 필요가 없다.
model.add(Activation('softmax')) #사용할 활성화 함수 지정
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']) #모델의 학습 방식에 대한 환경설정. loss => 모델의 최적화에 사용되는 목적함수.
optimizer => 정규화기. metrics => 기준 리스트. 분류 문제에 대해서는 metrics=['accuracy']로 설정한다.
참고자료
실습 : 파이썬을 이용한 머신러닝, 딥러닝 실전 개발 입문_ 쿠지라 히코우즈쿠에 저
https://keras.io/ko/layers/core/
Core Layers - Keras Documentation
[source] Dense keras.layers.Dense(units, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
keras.io
https://keras.io/ko/activations/
Activations - Keras Documentation
Activations의 이용 Activations는 Activation 층이나 앞선 층에서 지원하는 모든 activation argument로 이용 가능합니다: from keras.layers import Activation, Dense model.add(Dense(64)) model.add(Activation('tanh')) 이것은 다음과
keras.io
'Study > 머신러닝' 카테고리의 다른 글
| [6] 마르코프 체인과 LSTM으로 문장 생성하기 (0) | 2020.08.15 |
|---|---|
| [5] 문장의 유사도 분석하기 - 레벤슈타인 거리, N-gram (1) | 2020.08.06 |
| [3] 나이브 베이즈 분류를 사용한 텍스트 분류 (0) | 2020.07.25 |
| [2-2] Word2Vec을 활용해 문장을 벡터로 변환하기 (0) | 2020.07.17 |
| [2-1] KoNLPy 사용해서 한국어 형태소 분석하기(자연어 처리) (0) | 2020.07.16 |


