목차
1. 캐시 기억장치란?
- 중앙처리장치(CPU)에 명령어와 데이터를 빠르게 제공하기 위해 주기억장치에 저장되어 있는 명령어와 데이터 일부를 복사해서 임시로 저장하는 장치
- 주기억장치보다 명령어와 데이터를 저장하고 인출하는 속도가 빠름
- 빠르게 동작하는 중앙처리장치와 느리게 동작하는 주기억장치 사이에서 속도 차이를 줄여주는 완충제 역할을 하는 기억장치
- CPU는 주기억장치에 접근하기 전에 캐시 기억장치를 먼저 확인한다.
2. 캐시 기억장치 유무에 따른 시스템 동작원리
1) 캐시 기억장치가 없는 시스템
CPU가 명령어와 데이터를 인출하기 위해 주기억장치에 접근 -> 주기억장치에서 명령어와 데이터를 획득해 CPU 내의 레지스터에 저장
2) 캐시 기억장치가 있는 시스템
CPU가 명령어와 데이터를 인출하기 위해 캐시기억장치에 먼저 접근 -> CPU가 찾으려고 하는 데이터를 캐시 기억장치에서 찾으면 적중(hit)이라고 하고, 명령어를 찾지 못하면 실패(miss)라고 함.
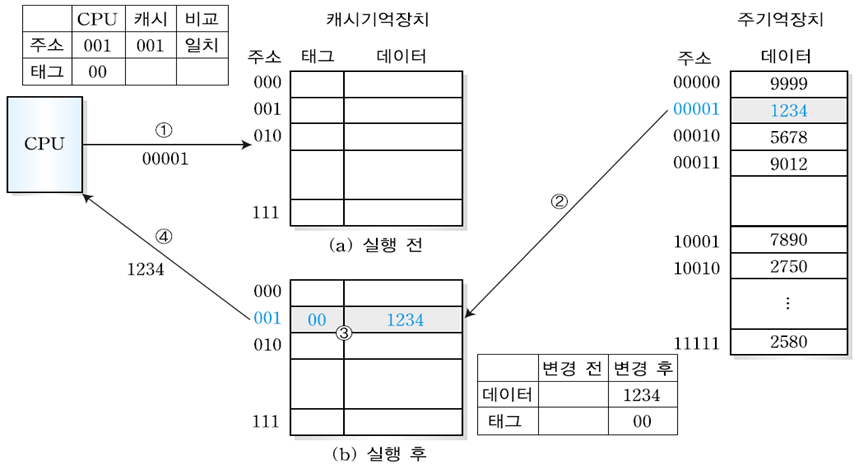
▶miss 예시
- CPU가 1000번지 워드를 필요로 할 때, 캐시 기억장치를 우선 검사한다. 현재 캐시기억장치가 비어 있는 상태이므로 miss 상태가 된다.
- miss 상태가 되면 주기억장치에서 필요한 정보를 획득해 캐시 기억장치에 전송하고, 캐시기억장치는 해당 정보를 다시 중앙처리장치로 전송한다.

▶hit 예시
- CPU가 1002번지 워드를 필요로 할 때, 캐시 기억장치가 해당 워드를 갖는지 검사한다. -> 캐시 기억장치에 해당 워드가 존재하므로 적중상태가 됨 -> 해당 정보를 중앙처리장치로 전송

다음 그림은 캐시기억장치의 동작원리를 순서도로 나타낸 것이다.

3. 캐시기억장치의 적중률
- 캐시기억장치의 적중률이 높을 수록 성능이 좋은 것이라고 판단할 수 있다.

|
Taverage |
주기억장치와 캐시기억장치에서 데이터를 인출하는데 소요되는 평균 기억장치 접근시간 |
|
Tmain |
주기억장치 접근시간 |
|
Tcache |
캐시기억장치 접근시간 |
|
Hhit_ratio |
적중률 |
Taverage = Hhit_ratio * Tcache + (1-Hhit_ratio) * Tmain
=> 적중률을 이용해 캐시기억장치와 주기억장치에 접근하는데 걸리는 평균 시간을 계산할 수 있다.
=> 적중률이 높아질수록 기억장치 접근시간이 줄어든다.
4. 캐시 기억장치의 설계시 고려할 요소
- 캐시 기억장치의 크기
- 인출 방식
- 사상함수
- 교체 알고리즘
- 쓰기 정책
- 블록 크기
- 캐시 기억장치의 수
1) 캐시 기억장치의 크기
- 캐시 기억장치의 크기가 클수록 주기억장치에서 많은 데이터를 가져올 수 있기 때문에
적중률이 높아진다. 하지만, 크기가 커진 만큼 캐시를 검사하는 시간이 오래 걸리기 때문에 평균 접근 시간이 증가한다. 또한 캐시는 크기가 클수록 비싸서 비용도 증가한다.
- 이런 점을 고려해서 적중률을 향상시키고 평균 접근시간이 증가하는 것을 막는 최적의 크기를 찾아야 함
- 연구 결과에 의하면 캐시 기억장치의 크기로는 1K~128K word가 최적이라고 알려짐
2) 인출 방식
- 캐시 기억장치가 주기억장치에서 명령어와 데이터 블록을 인출하는 방식
① 요구인출(Demand Fetch) 방식
- CPU가 필요로 하는 정보만을 주기억장치에서 블록 단위로 인출하는 방식
② 선인출(Prefetch) 방식
- CPU가 필요로 하는 정보와 나중에 필요로 할 것이라 예측되는 정보를 미리 인출하는 방식
- 주기억장치에서 명령어나 데이터를 인출할 때 필요한 정보와 이웃한 위치의 정보들을 함께 인출하는 방식(현재 필요한 데이터에 근접한 데이터를 나중에 필요할 것이라고 예측한 것임)
3) 사상(mapping) 함수
- 사상(mapping) : 주기억장치와 캐시기억장치 사이에서 정보를 옮기는 것
*사상 방법에 대해 알아보기 전에 주기억장치와 캐시기억장치의 구조에 대해 알아보자

▶주기억장치의 구조
- 워드(word) : 하나의 주소 번지에 저장되는 데이터의 단위
- 블록(block) : k개의 워드로 구성됨
▶캐시기억장치의 구조
- 슬롯(slot) : 데이터 블록이 저장되는 곳
- 태그(tag) : 슬롯에 적재된 데이터 블록을 구분해주는 정보
- 사상 방법에는 직접 사상, 연관 사상, 집합 연관 사상이 있다.
① 직접 사상(direct mapping)
- 주기억장치의 데이터 블록 주소 = 캐시 기억장치 데이터 블록 슬롯번호(주소) + 데이터 블록 태그
- 장점 : 사상 과정이 간단함
- 단점 : 동일 슬롯 번호를 갖지만 태그가 다른 데이터 블록들에 대한 반복적인 접근은 적중률을 떨어뜨림
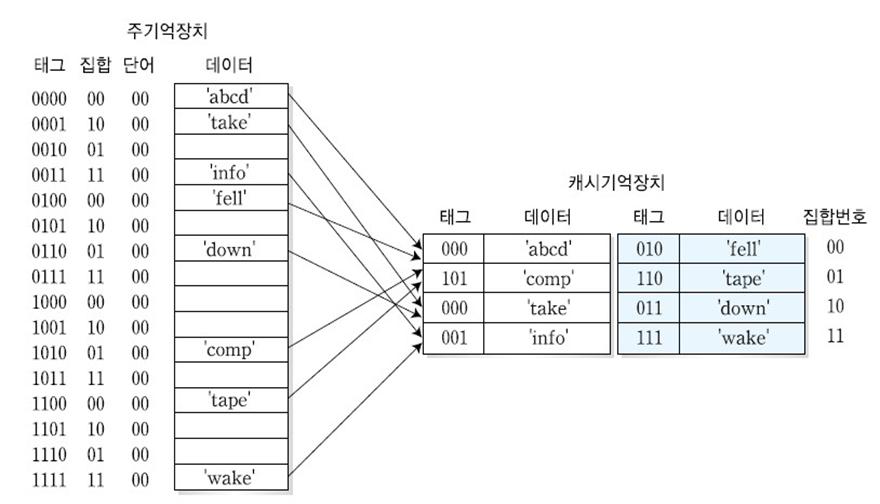
② 연관 사상
- 캐시 슬롯번호에 상관없이, 주기억장치의 데이터 블록을 캐시 기억장치의 임의의 위치에 저장하는 것
- 캐시기억장치에서 데이터 블록을 인출할 때 모든 슬롯에 대한 검색이 필요함
- 주기억장치 데이터 블록 주소 = 캐시기억장치 데이터 블록 태그

③ 집합 연관 사상
- 직접 사상과 연관 사상 방식을 합친 방식
- 캐시는 v개의 집합들로 나누어지고, 각 집합들은 k개의 슬롯들로 구성됨
- 직접 사상 방식에 의해, v개의 집합 중에서 하나의 집합을 선택함
- 연관 사상 방식에 의해, 선택한 집합 내에 있는 k개의 슬롯 중에서 하나의 슬롯을 선택함
- 주기억장치 데이터 블록 주소 = 캐시기억장치 데이터 블록 집합번호 + 데이터 블록 태그
4) 교체 알고리즘
- 캐시 기억장치의 모든 슬롯이 꽉 차 있어서 실패(miss)일 때, 주기억장치에서 새로운 데이터 블록을 캐시 기억장치에 가져오기 위해 캐시 기억장치의 어떤 슬롯 데이터를 제거할지 결정하는 방식
- 직접 사상 : 교체 알고리즘이 필요 없음
- 연관 & 집합 연관 사상 : 교체 알고리즘이 필요함
▶종류
- LRU (Least Recently Used) : 최소 최근 사용 알고리즘
- LFU (Least Frequently Used) : 최소 사용 빈도 알고리즘
- FIFO (First In First Out) : 선입선출 알고리즘
- RANDOM : 랜덤
5) 쓰기 정책
- CPU가 프로그램을 실행하다가 연산 결과를 캐시기억장치에 저장하는 경우가 있다. 캐시에 저장된 데이터를 주기억장치도 가져야 하기 때문에 주기억장치에 데이터를 갱신하는 방법을 쓰기 정책으로 결정
① 즉시 쓰기(Write-though) 방식
- CPU에서 생성되는 데이터 블록을 캐시기억장치, 주기억장치에 동시에 기록하는 것
- 장점 : 데이터의 일관성이 쉽게 보장된다
- 단점 : 매번 쓰기 동작을 할 때마다, 캐시기억장치와 주기억장치 간 접근이 빈번하게 일어나고 쓰기 시간이 길어짐
② 나중 쓰기(Write-back) 방식
- 캐시기억장치에 기록한 후, 기록된 블록에 대한 교체가 일어날 때, 주기억장치에 기록하는 것
- 장점 : 주기억장치에 기록하는 동작을 최소화할 수 있음
- 단점 : 캐시기억장치와 주기억장치의 데이터가 일치하지 않을 수 있음
6) 블록 크기
- 블록의 크기가 클수록 한번에 많은 정보를 읽어 올 수 있음. 하지만, 블록 인출 시간이 길어짐
- 블록이 커질수록 캐시 기억장치에 적재할 수 있는 블록의 수가 감소하기 때문에 블록이 더 자주 교체됨
- 일반적인 블록 크기 : 4~8 워드가 적당
7) 캐시의 수
- 시스템 성능 향상을 위해 다수의 캐시기억장치들을 사용하는 것이 보편화됨
- 캐시기억장치들을 계층적 구조나 기능적 구조로 설치함
- 가장 일반적인 구조는 한 개의 캐시기억장치를 사용하는 형태임
문제
1. 다음은 캐시기억장치에 대한 설명이다. 맞으면 O, 틀리면 X. 틀렸다면 알맞게 고치세요.
| 캐시기억장치는 CPU안에 존재하는 기억장치다. |
2. 적중률이 65%, 캐시기억장치 접근시간이 50ns, 주기억장치 접근시간이 410ns일 때, 평균 기억장치 접근 시간을 계산하시오.
3.
| 즉시 쓰기 정책을 사용하면 데이터의 ( )이 쉽게 보장된다. |
6. 다음 중 집합 연관 사상에 대한 설명으로 옳은 것을 고르세요.
ㄱ. 사상 과정이 간단하다.
ㄴ. 캐시 기억장치에서 데이터 블록을 인출할 때 모든 슬롯을 검색해야 한다.
ㄷ. 캐시는 집합들로 나누어지고, 각 집합들은 슬롯들로 구성됨
ㄹ. 태그가 다른 데이터 블록들에 대한 반복적인 접근이 발생한다.
7. 다음 빈칸에 들어갈 알맞은 말은?
| 캐시 기억장치가 있는 시스템에서 CPU가 명령어와 데이터를 인출하기 위해 캐시기억장치에 접근했을 때 CPU가 찾으려고 하는 데이터를 캐시 기억장치에서 찾으면 ( )이라고 한다. |
정답/해설
1. X
- 캐시기억장치는 CPU 밖에 존재하는 기억장치다.
2. 176ns
- Taverage = Hhit_ratio * Tcache + (1-Hhit_ratio) * Tmain 식에 따라서 계산하면 0.65*50+0.35*410=176ns 이다.
3. ㄹ
- 캐시기억장치를 설계할 때 고려하는 요소는 캐시 기억장치의 크기, 인출 방식, 사상함수, 교체 알고리즘, 쓰기 정책, 블록 크기, 캐시 기억장치의 수
4. O
- 인출 방식 중 CPU가 필요로 하는 정보만을 주기억장치에서 블록 단위로 인출하는 방식을 요구 인출, CPU가 필요로 하는 정보와 나중에 필요로 할 것이라 예측되는 정보를 미리 인출하는 방식을 선인출 방식이라고 한다.
5. 일관성
- 즉시 쓰기 정책을 사용하면 CPU에서 생성되는 데이터 블록을 캐시기억장치, 주기억장치에 동시에 기록하기 때문에 데이터의 일관성이 쉽게 보장된다.
6. ㄷ
ㄱ. 사상 과정이 간단하다. => 직접 사상에 대한 설명이다.
ㄴ. 캐시 기억장치에서 데이터 블록을 인출할 때 모든 슬롯을 검색해야 한다. => 연관 사상에 대한 설명이다.
ㄷ. 캐시는 집합들로 나누어지고, 각 집합들은 슬롯들로 구성됨
ㄹ. 태그가 다른 데이터 블록들에 대한 반복적인 접근이 발생한다. => 직접 사상에 대한 설명이다.
7. 적중(hit)
- 적중은 CPU가 명령어와 데이터를 인출하기 위해 캐시기억장치에 접근했을 때 CPU가 찾으려고 하는 데이터를 캐시 기억장치에서 찾았을 때를 말한다.
문제
1. 다음 중 보조기억장치가 아닌 것은?
ㄱ. 하드 디스크
ㄴ. RAM
ㄷ. 플로피디스크
ㄹ. CD
2. 하드 디스크와 플로피 디스크가 데이터에 접근하는 방법은 무엇인가?
3. 입출력 장치 제어 기법 중 중앙처리장치가 직접 제어하는 방식 중 중앙처리장치가 입출력 모듈의 데이터 송수신 준비를 기다리지 않고 수행중인 프로그램을 계속 진행할 수 있는 방식은 무엇인가?
4. 시스템 버스 중 단방향 전송만 가능한 것은?
5. 입출력장치가 주기억장치에 직접 액세스해서 입출력 장치를 제어할 때 사용되는 DMA 제어기의 구성 요소가 아닌 것은?
ㄱ. 주소 레지스터
ㄴ. 명령어 레지스터
ㄷ. 계수 레지스터
ㄹ. 데이터 레지스터
정답/해설
1. ㄴ
- RAM은 주기억장치다.
2. 직접 접근
- 하드 디스크, 플로피 디스크, CD-ROM, DVD 등은 원하는 데이터가 저장된 기억장소 근처로 이동한 뒤, 순차적 검색을 통해서 원하는 데이터에 접근하는 방법인 직접 접근 방법을 사용한다.
3. 인터럽트 구동 입출력 방식
- 이 방식은 중앙처리장치가 인터럽트를 발생시켜서 입출력 모듈에 입출력 작업의 개시를 지시하는 방식이다. 입출력 모듈이 데이터 송수신 준비를 할 때까지 기다리지 않고 수행중인 프로그램을 계속 진행할 수 있다.
4. 주소 버스
- 데이터 버스는 서로 보낼 수 있는 양방향 버스이고, 제어 버스는 단방향, 양방향 모두 가능하다.
주소 버스는 주소를 전송하기 위한 것이라서 단방향 전송만 가능하다.
5. ㄴ
- DMA 제어기는 주소 레지스터, 데이터 레지스터, 계수 레지스터, 제어회로로 구성된다.
'Study > 컴퓨터구조' 카테고리의 다른 글
| [6] MIPS 시스템 (0) | 2020.06.09 |
|---|---|
| [4] 분기 명령어와 오퍼랜드 개수에 따른 명령어 형식 (3) | 2020.05.30 |
| [3-2] 메모리 구조와 레지스터 종류 (0) | 2020.05.23 |
| [3-1] 컴퓨터 명령어 실행 기법 (0) | 2020.05.22 |
| [2-2] 컴퓨터의 명령어 (0) | 2020.04.17 |


