목차
컴퓨터의 명령어를 효과적으로 실행하는 다양한 기법이 존재한다. 기법들에 대해 자세히 알기 전, 명령어가 어떤 식으로 구성되었는지 확인해보자. (이 글에서 말하는 명령어는 인텔 8086 프로세서의 명령어 형식을 따른다.)
명령어는 연산코드와 오퍼랜드로 구성되어 있다.
연산코드는 말 그대로 CPU가 실행할 수 있는 연산을 나타내는 연산코드가 들어간다.
오퍼랜드는 연산이 이루어지는 대상의 데이터 또는 데이터의 주소가 들어간다.
이런 명령어를 효과적으로 실행하는 기법은 크게 3가지가 있다.
1. 주소 지정 방식
2. 파이프라인
3. 인터럽트
1. 주소 지정 방식
- 명령어를 실행하기 위해서는 연산을 하기 위한 데이터가 무엇인지 알아야한다. 그래서 명령어에는 연산의 대상이나 대상의 주소를 저장하는 오퍼랜드가 존재한다. 주소 지정 방식은 오퍼랜드에 들어갈 주소를 지정하는 방식이다. 여기서 주소는 주기억장치에 저장된 데이터의 위치를 말한다.
- 주소를 지정하는 방식에는 직접 주소지정 방식, 간접 주소지정 방식, 레지스터 주소지정 방식, 레지스터 간접 주소지정 방식, 변위 주소지정 방식이 있다.

1) 직접 주소지정 방식
- 가장 일반적이고 간단한 방식
- 오퍼랜드의 값이 유효 주소(기억장치의 실제 주소)가 되는 방식
- 명령어를 실행할 때, 바로 주기억장치로 가서 값을 가져오면 됨
- EA = A (유효 주소 = 기억장치 주소)

장점
- 주기억장치에 한 번만 액세스 => 장점인 이유 : 명령어를 빠르게 처리하려면 주기억장치에 최대한 적게 액세스 하는 것이 좋기 때문에 한 번만 액세스 한다는 것은 명령어를 빠르게 처리할 수 있어서 장점이다.
- 간단한 명령어 형식
단점
- 연산 코드로 사용하고 남은 비트들을 이용해 주소를 표현해야 하기 때문에 주소가 길면 지정할 수 없음
- 많은 수의 주소를 지정할 수 없음
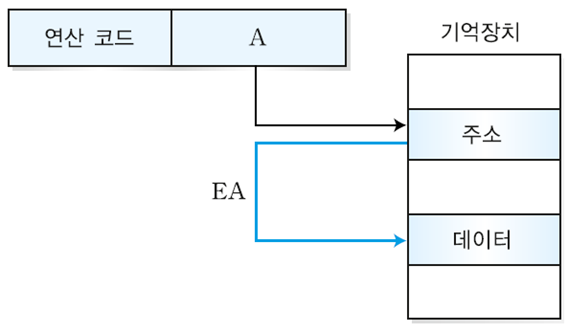
2) 간접 주소지정 방식
- 직접 주소지정 방식의 단점(긴 주소는 지정할 수 없음)을 개선한 방식
- 오퍼랜드의 값이 유효 주소의 주소가 되는 방식
- 오퍼랜드의 값을 보고 주기억장치에 가면 주소 값이 적혀있고 또 그 주소로 가보면 실제 연산에 사용될 데이터가 존재하는 것이다.
- 주기억장치에 총 2번 액세스함
- EA = (A)
장점
- 워드가 N워드면 2의 N승의 주소 공간을 사용할 수 있음
- 기억장치의 구조 변경 등을 통해 확장할 수 있음
- 명령어에서 연산 코드로 사용하고 남은 비트가 적어도 긴 주소에 접근할 수 있음
단점
- 두 번의 주기억장치 액세스가 필요하기 때문에 직접 주소 지정 방식보다 속도가 느림
- 명령어 형식에서 어떤 주소 지정 방식을 사용하는지 표시하는 간접비트가 필요함.
- I가 주소 지정 방식을 표현하는 비트다.
- I가 0일 때 : 직접 주소 지정 방식
- I가 1일 때 : 간접 주소 지정 방식

3) 레지스터 주소지정 방식
- 레지스터에 연산에 사용될 데이터가 저장되어 있는 방식
- 오퍼랜드에는 레지스터의 번호가 저장되어 있다. 그 레지스터에 가면 연산할 데이터가 존재함
- EA = R
장점
- 많은 비트가 필요하지 않음
- 주기억장치에 액세스할 필요가 없음
단점
- 데이터를 저장할 공간이 CPU 내부의 레지스터로 제한됨 (레지스터는 비싸고 용량은 적다 하지만 속도는 빠름)
4) 레지스터 간접 주소지정 방식
- 오퍼랜드에 레지스터 번호가 저장되어 있고, 그 레지스터에 가면 유효주소가 저장되어 있다. 그러면 주기억장치의 그 주소로 가서 데이터를 읽는 방식이다.
- 레지스터의 길이에 따라 주소 범위가 결정됨 => 만약 레지스터의 길이가 16비트라면 주소 범위는 2의 16승 비트까지 저장할 수 있다.
- EA = (R)

장점
- 더 많은 주소 공간을 활용할 수 있음
단점
- 간접 주소 방식보다는 주기억장치에 덜 액세스하지만, 여분의 메모리 참조(레지스터)가 필요함
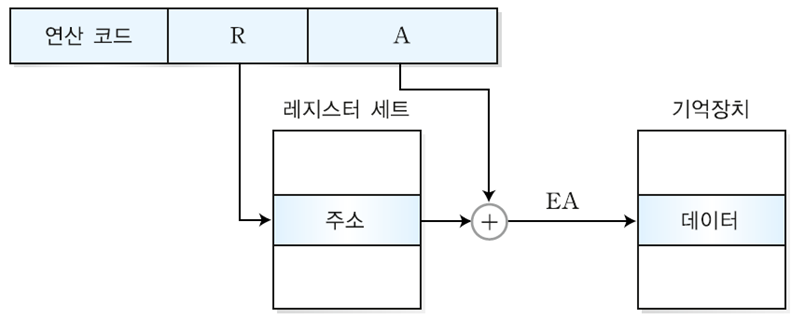
5) 변위 주소 지정 방식
- 직접 주소 지정 방식 + 레지스터 간접 주소 지정 방식
- 오퍼랜드에는 레지스터 번호와 변위 값이 저장되어있다.
- 오퍼랜드에 있는 레지스터 번호에 해당하는 레지스터로 가면 그곳에 주소값이 저장되어 있음 ->
주소값 + 변위값 = 연산에 사용될 데이터가 있는 유효주소
- 변위 값은 양수/음수 모두 표현 가능함
- 변위 주소 지정 방식은 사용하는 레지스터에 따라 3가지 방식이 있다. 상대 주소 지정방식, 인덱스 주소 지정 방식, 베이스 레지스터 주소 지정 방식
- EA = (R) + A
① 상대 주소 지정 방식
- 변위 주소 지정 방식에서 프로그램 카운터(PC)를 레지스터로 사용한 방식
- 주로 분기 명령어에서 사용됨
- EA = (PC) + A
- EX) 400번지에 저장되어 있던 JUMP 명령어가 인출된 후, PC 값이 401이 되었을 때, A(변위)값이 +30 이면 분기 목적지 주소는 431이다.
② 인덱스 주소 지정방식
- 변위 주소 지정 방식에서 인덱스 레지스터를 사용한 방식
- 인덱스 레지스터 : 인덱스 값을 저장하는 레지스터
- EA = (IX) + A
- 명령어가 실행되면 인덱스 레지스터의 내용(인덱스 값)이 자동으로 증가 혹은 감소함
③ 베이스 레지스터 주소 지정 방식
- 변위 주소 지정 방식에서 베이스 레지스터를 사용한 방식
- 베이스 레지스터에 저장된 값과 변위 A를 더하면 유효주소임
- EA = (BR) + A
2. 명령어 파이프 라인
- 한 명령어가 실행되는 도중에 다른 명령어 실행을 시작해서 동시에 여러 개의 명령어를 실행하는 방법
- 하나의 명령어를 여러 단계로 나누어서 처리할 수 있어서 처리 속도가 빨라질 수 있음
- 종류 : 2단계 명령어 파이프라인, 4단계 명령어 파이프라인, 6단계 명령어 파이프라인
1) 2단계 명령어 파이프라인
- 명령어 실행을 인출 단계, 실행 단계로 분리해서 수행하는 방법
- 두 단계는 독립적이다. 명령어를 인출하는 일만 하는 하드웨어와 실행하는 일만 하는 하드웨어가 따로 존재한다고 생각하면 된다.

2) 4단계 명령어 파이프라인
- 명령어 실행이 4단계(명령어 인출, 명령어 해독, 오퍼랜드 인출, 명령어 실행)로 구성된 파이프라인
- 명령어 인출(IF, Instruction Fetch) 단계 : 주기억장치에서 명령어를 인출해 명령어 레지스터로 이동시키는 단계
- 명령어 해독(ID, Instruction Decode) 단계 : 명령어 해독기를 이용해 명령어의 연산 코드를 해석하는 단계
- 오퍼랜드 인출(OF, Operation Fetch) 단계 : 연산에 사용될 데이터를 인출하는 단계
- 실행(EX, Execute) 단계 : 명령어의 연산을 실행하는 단계

3) 6단계 명령어 파이프 라인
- 명령어를 실행하는 단계가 6단계로 구성된 파이프라인
- 명령어 인출, 명령어 해독, 오퍼랜드 계산, 오퍼랜드 인출, 명령어 실행, 오퍼랜드 저장
- 명령어 인출, 명령어 해독, 오퍼랜드 인출, 명령어 실행단계에서는 4단계 명령어 파이프 라인이 하는 일과 동일한 일을 수행한다.
- 오퍼랜드 계산(CO, Calculate Operand) 단계 : 연산에 필요한 실제 데이터가 있는 유효주소를 찾기 위한 단계
- 오퍼랜드 저장(WO, Write Operand) 단계 : 연산된 결과를 저장하는 단계

* 파이프 라인에 의한 속도 향상
- 명령어 실행 시간을 계산하는 방법
- k : 파이프라인의 단계 수 (2, 4, 6)
- N : 실행할 명령어들의 수
- 각 파이프라인의 단계 : 한 클록 주기씩 소요됨
- T : 파이프라인을 적용해서 N개의 명령어를 실행하는데 소요되는 시간
=> T = k + (N - 1)
- T' : 파이프라인을 적용하지 않고 N개의 명령어를 실행하는데 소요되는 시간
=> T' = k * N
3) 인터럽트
- CPU가 실행하고 있는 프로그램의 처리를 강제로 중단하고 다른 프로그램을 수행하는 것
- 인터럽트 처리 과정 : 인터럽트가 시작되면, 현재 실행 중인 프로그램의 중요 데이터가 주기억장치에 저장되고 실행중인 프로그램은 중단된다. 중단된 프로그램은 인터럽트가 다 처리된 후에 실행됨
*발생 원인에 따른 인터럽트 종류
① 기계 착오 인터럽트
- 정전이나 CPU 등 컴퓨터 자체 내의 기계적인 문제로 인해 발생하는 인터럽트
② 슈퍼바이저 호출 인터럽트
- 슈퍼바이저 호출(SVC) 명령어를 사용하여 운영체제에 서비스를 요청할 때 발생하는 인터럽트
③ 외부 인터럽트
- 오퍼레이터나 타이머에 의해 의도적으로 프로그램이 중단된 경우 발생하는 인터럽트
④ 입출력 인터럽트
- 입출력의 종료나 오류에 의해 CPU의 기능이 요청되는 경우 발생하는 인터럽트
- EX) 사용자의 입력이 필요할 때 제어권을 입출력장치에 넘겨주고 나서 입력이 끝나면 다시 CPU에게
제어권을 돌려주기 위해 인터럽트를 발생시킴
⑤ 프로그램 검사 인터럽트
- 프로그램을 실행하고 있는 도중 보호된 기억 공간 내에 접근하거나 불법적인 명령 수행 같은 프로그램의 문제로 인해 발생하는 인터럽트
- EX) 오버플로우, 0으로 나누기, 언더플로우, 부당한 기억장소의 참조, 프로그램에서 명령어를 잘못 사용한 경우
⑥ 재시작 인터럽트
- 오퍼레이터 및 다른 프로세서에 의해 재시작 명령이 오면 발생하는 인터럽트
*인터럽트 처리
- 인터럽트 사이클 : 인트럽트 발생을 처리하기 위해 인터럽트 요구가 있는지 검사하는 과정
- 만약 인터럽트 요구가 없다 => 다음 명령어를 인출하는 인출 사이클을 실행한다
- 만약 인터럽트 요구가 있다 => 인터럽트 사이클에 의해 현재 CPU가 실행하고 있던 프로그램의 상태를 저장한 뒤, 프로그램 실행을 중단한다. -> 프로그램 카운터를 인터럽트 처리 루틴의 시작 주소로 설정하고 인터럽트를 처리한다. -> 인터럽트 처리가 끝나면 다시 명령어 인출을 시작한다.

*다중 인터럽트 처리
- 인터럽트를 처리하고 있는 도중 또 다른 인터럽트가 발생하는 것
- 처리 방식 : 순차적인 다중 인터럽트 처리, 우선순위 다중 인터럽트 처리
① 순차적인 다중 인터럽트 처리
- 기존에 처리하고 있는 인터럽트가 있으면 중간에 새로운 인터럽트 요구가 발생하더라도 CPU가 새로운 인터럽트 사이클을 수행하지 않음
- 중간에 발생한 인터럽트는 대기상태에 있다가 처리하고 있던 인터럽트를 다 처리한 다음에 인터럽트가 발생한 순서대로 처리함
② 우선순위 다중 인터럽트 처리
- 인터럽트의 우선 순위를 정해서 우선순위대로 처리함
- 실행하고 있던 인터럽트와 중간에 발생한 인터럽트의 우선 순위를 비교해서 새로운 인터럽트의 우선순위가 더 높다면, 실행하고 있던 인터럽트 처리를 중단하고 새로운 인터럽트를 처리함
문제
1. 변위 주소 지정 방식에서 변위 값은 음수가 올 수 있다. (O / X)
2. 6단계 명령어 파이프라인에 추가된 단계는 무엇인가? (4단계 명령어 파이프라인과 비교해서)
3. 6단계 파이프라인을 적용해서 13개의 명령어를 실행하는데 걸리는 시간은?
4. 프로그램을 실행 중일 때, 프로그램에서 잘못된 명령어가 사용되었다. 이때 발생하는 인터럽트의 종류는?
5. 간접 주소 지정 방식에서 개선된 직접 주소지정 방식의 단점은 무엇인가?
6. 상대 주소 지정 방식에서 사용하는 레지스터는 무엇인가?
7. 인터럽트 사이클에서 인터럽트 요구가 없을 때 발생하는 일은?
8. 명령어 파이프라인의 4단계, 6단계에 있는 오퍼랜드 인출 단계에 대한 설명이다. 괄호에 들어갈 말은?
=> 오퍼랜드 인출 단계는 연산에 사용될 ( )를 인출하는 단계이다.
9. 주소 지정 방식 중 레지스터 주소 지정 방식은 많은 비트 수가 필요하지 않다. (O / X)
10. 'EA = (R)'이 의미하는 주소 지정 방식은 무엇인가?
정답/해설
1. O
- 변위 값은 양수/음수 모두 올 수 있다.
2. 오퍼랜드 계산 단계, 오퍼랜드 저장 단계
- 6단계 명령어 파이프라인에는 연산에 필요한 실제 데이터가 있는 유효주소를 찾기 위한 단계인 오퍼랜드 계산 단계와 연산된 결과를 저장하는 오퍼랜드 저장 단계가 추가되었다.
3. 18
- 파이프라인을 적용했을 때 걸리는 시간은 k(파이프라인의 단계 수) + {N(명령어 개수) - 1}이므로
6 + (13-1) = 18 이다.
4. 프로그램 검사 인터럽트
- 프로그램 검사 인터럽트는 오버플로우, 0에 의한 나누기, 언더플로우, 부당한 기억장소의 참조 그리고 프로그램에서 잘못된 명령어를 사용했을 경우에 발생한다.
5. 긴 주소는 지정할 수 없는 것
- 직접 주소 지정 방식은 연산 코드로 사용하고 남은 비트들을 이용해 주소를 표현해야하기 때문에 주소가 길면 지정할 수 없다는 단점이 있다. 간접 주소 지정 방식은 오퍼랜드의 값이 유효 주소의 주소가 되는 방식이라서 직접 주소 지정 방식보다 더 긴 주소를 지정할 수 있다.
6. 프로그램 카운터
- 상대 주소 지정 방식은 변위 주소 지정 방식에서 프로그램 카운터를 레지스터로 사용한 방식으로, 주로 분기 명령어에서 사용된다.
7. 명령어 인출
- 인터럽트 요구가 없으면 다시 인출 사이클로 돌아가 명령어 인출을 한다.
8. 데이터
- 오퍼랜드 인출 단계는 연산에 사용될 데이터를 인출하는 단계이다.
9. O
- 레지스터 주소 지정 방식은 오퍼랜드에 레지스터의 번호만 저장하면 되기 때문에 많은 비트 수가 필요하지 않다.
10. 레지스터 간접 주소 지정 방식
- 레지스터 간접 주소 지정 방식은 오퍼랜드에 레지스터 번호가 저장되어 있고, 그 레지스터에 가면 유효주소가 저장되어 있어서 주기억장치의 그 주소로 가서 데이터를 읽는 방식이다.
'Study > 컴퓨터구조' 카테고리의 다른 글
| [4] 분기 명령어와 오퍼랜드 개수에 따른 명령어 형식 (3) | 2020.05.30 |
|---|---|
| [3-2] 메모리 구조와 레지스터 종류 (0) | 2020.05.23 |
| [2-2] 컴퓨터의 명령어 (0) | 2020.04.17 |
| [2-1] 컴퓨터 정보의 표현 (0) | 2020.04.17 |
| [1주차] 컴퓨터의 기본 구조와 CPU (0) | 2020.04.10 |

